浅谈监管分析中的数据挖掘
数据挖掘,又称为数据库中的知识发现(Knowledge Discoveryin Database,KDD),就是从存放在数据库、数据仓库或其他信息库中的大量的数据中“挖掘”或“找到”有趣知识的过程。近年来,数据挖掘引起了信息产业界的极大关注,其主要原因是存在大量数据,可以广泛使用,并且迫切需要将这些数据转换成有用的信息和知识。获取的信息和知识可以广泛用于各种应用,包括行业监管、商务管理、生产控制、市场分析、工程设计和科学探索等。
有一个“尿布与啤酒”的故事,可以用来说明数据挖掘的作用。沃尔玛数据仓库里集中了其各门店的详细原始交易数据。沃尔玛在这些原始交易数据的基础上,利用数据挖掘技术方法对这些数据进行分析和挖掘。一个意外的发现是:跟尿布一起购买最多的商品竟是啤酒!经过大量实际调查和分析,发现美国的太太们常叮嘱她们的丈夫下班后到超市为小孩买尿布,而丈夫们中有30%~40%的人在买尿布的同时也为自己买一些啤酒。于是沃尔玛干脆将尿布与啤酒摆在同一个货架上,从而更方便了顾客,促进了销售。按常规思维,尿布与啤酒风马牛不相及,若不是借助数据挖掘技术方法对大量交易数据进行挖掘分析,沃尔玛是不可能发现数据内在这一有价值的规律的。
那么,怎么样来挖掘数据呢?
首先,要解决员工动力问题。就是要教育员工坚持做到忠恕(推已及人)、紧跟(与时俱进)、创新(推陈出新)和兼顾(同心协力)等四项原则,从根本上解决员工的思想政治问题。
一是忠恕:忠者,心无二心,意无二意之谓,恕者,了己了人,明始明终之意。其关键是推已及人:“忠”,具有“尽己为人”之心,待人真诚之魂;“恕”,具有“以己度人”之意,待人宽容之道。把“忠”、“恕”这两方面合起来,就叫做忠恕之道。忠恕之道能够解决员工的政治思想问题,培育员工的忠诚感恩之心,提升员工的责任心和事业感,促进员工的工作激情,激发员工的生活情趣。
二是紧跟:就是紧追不舍,不放弃、不抛弃。在工作上、学习上、思想上能够坚持不掉队、不落伍,始终与上级保持一致,进而准确把握时代特征,其实质是具有与时俱进。“紧”,具有紧迫感特征,充满着拉力和压力。“跟”,具有不掉队精神,贯穿着耐力和毅力。把“紧”、“跟”联系在一起就叫做紧跟之心、紧跟之心能够解决员工的惰性和麻痹问题,促使员工不断改进工作方法,不断提升思想认识和理论水平,始终向先进者看齐。在观念上和行动上无限缩小与上级和同事的差距。
三是创新:是对于重复、简单的劳动方式的否定,是对于人类实践范畴的超越,其关键在于推陈出新。“创”,是知识经验等积累的肯定方面,具有广泛性和深刻性,是无限的。“新”,是对方式方法等形态的否定方面,具有逆向性,是一种“怀疑”,是永无止境的。把“创”和“新”结合起来就叫创新之举。创新之举能够解决员工的守旧情绪和熟视无睹的问题,激发员工变异思维,不断创造新思想、新工艺、新方法和新产品,在各个方面都会有所超越、有所发现,从而不断推进行业、社会、民族乃至全人类的进步。
四是兼顾:要除了做好本职工作以外,还要有大局意识,做到局部服务全局,能够克服困难,努力完成各级领导交办的其他工作。其核心是同心协力。“兼”,是一种承载,是一种胸怀,是同心协力的方向。“顾”,是一种完善,是一种包容,是同心协力的目标。把“兼”和“顾”揉合在一起就是兼顾之怀。兼顾之怀能够解决狭隘的个人主义、山头主义思想问题,不仅能够排除行业团结的障碍,而且能够增强行业的战斗力。从而不断整合人力资源,把局部胜利推向全局胜利,不断促使部门、行业及至更大范围内的胜利。
其次,要解决方法问题。就是要通过读活数据(传统方法)、知识运用(推理方法)、大海捞针(筛选方法)、专业软件(技术方法)等方法或手段,挖掘出有用数据。
一是读活数据——传统方法。通过阅读政策、理论和报表数据,运用政策传导和理论根据,去挖掘数据背后的真实状况。在阅读的基础上,进一步计算比较基础数据的增加值、增长率和标准值等变化规律,及时发现各指标在运行过程中发生的突变情况。在阅读、比较的基础上进一步分析。
分析实例一:利率对银行的影响。2007年12月21日到2008年12月23日,央行连续4次下调基准利率,假设在银行存贷款总额不变的情况下,存、贷款人和银行的利息收支变化情况如下表:
|
利率对银行的影响
|
|||||
|
单位:万元
|
一年期基准利率
|
应付利息
|
应收利息
|
利差
|
|
|
存款
|
贷款
|
|
|
|
|
|
20071221前
|
4.14
|
7.47
|
89250.87
|
114284.29
|
25033.42
|
|
20081223前
|
2.52
|
5.58
|
54326.61
|
85368.99
|
31042.37
|
|
20081223后
|
2.25
|
5.31
|
48505.91
|
81238.23
|
32732.32
|
|
余额
|
2155818.03
|
1529910.18
|
|
|
|
|
|
比20071221
|
差额
|
-34924.25
|
-28915.30
|
6008.95
|
|
|
比20081223
|
差额
|
-5820.71
|
-4130.76
|
1689.95
|
|
每下调27个基点的利息收入增加1689.95万元
|
-5820.71
|
-4130.76
|
1689.95
|
||
从银行的角度来看,当基准利率下调时,支付的存款利息和收到的贷款利息都会减少,而且在存贷比保持某个比例时,利差会增大,而不是通常人们认为的那样利差会减少。从消费者的角度来看,存款人少收的利息大于贷款人少付的利息,结果银行增加的收入来自存款人减少的收入。
二是知识运用——推理方法。通过理论知识实证或者预测现实世界。
分析实例二:奥肯定律实证分析。失业率每上升一个百分点,实际GDP的增长率就下降两个百分点。2008年,全年国内生产总值同比增长9.0%。如果2009年GDP增长8.0%,则实际下降1个百分点,根据奥肯定律,失业率应上升0.5个百分点,达到4.7%。
分析实例三:GDP与投资的关系。理论上,在投资拉动型的国家或地区,GDP增长一个点,需要投资增长2个点。因此,用GDP与投资总量之间的这种理论关系,可以推算出非信贷投资总额。2008年保山市GDP增长率为13.1%(G),从GDP增速倒推,与其相适应的投资增速应在26.2%左右,但本地银行贷款实际增长22.27亿元,增速仅为16.84%,少增9.36%,表明有其他资金投放在本地;年初贷款余额N=131.79亿元,S=N×G×2-M=131.79×13.1%×2-22.27=12.37亿元。表明外地资金在本地当年投放12.37亿元左右。
分析实例四:金融危机与菜农的关系。美国金融危机后==>中国涉外企业十分困难,大多处于于关停状态==>大量农民工返乡==>返乡后自己种蔬菜(再说也无法买到原来吃的蔬菜)==>以往这些农民工日常消费的蔬菜没有人消费,形成消费链断裂==>河南菜农的蔬菜卖不出去==>河南菜农生产过剩。事实上,根据国新办于2009年2月2日上午10时举行新闻背景吹风会,离开本乡镇外出就业的农民工的总量大概是1.3亿人,大约有15.3%的农民工因全球金融危机而失去了工作,或者没找到工作。据此推算,全国大约有2000万农民工失去工作,或者还没有找到工作而返乡了。假设每个农民工日均消费1市斤蔬菜,返乡农民工有2000万,就意味着菜农每天有2000万斤蔬菜卖不出去。
三是大海捞针——筛选方法。通过Excel的筛选命令,可以从众多的数据中筛选出需要的信息。
分析实例五:异地贷款统计。在《非现场监管信息系统》中,没有对异地贷款信息专门统计,给异地贷款风险监管带来难度,可是,《风险预警系统》给我们提供了丰富的客戶信息资源。《风险预警系统》中包含了哪个银行在什么地方对哪个企业授信多少、发放贷款多少,以及现在贷款的质量怎么样等48项信息。当银行与企业不在同一个地方时,贷款就衍变为异地贷款,考察全省汇总数据,我们很快发现,可以用筛选方法,将异地贷款统计出来。方法是:分别用筛选命令,筛选出注册地在本地各县区的所有客户,并将其汇总在同一张Excel表中,再删除本地银行机构的客户信息,剩下的就是外地银行在本地客户的贷款信息。反之,也可以筛选出本地银行在外地客户的贷款信息。
四是专业软件——技术方法。通过《非现场监管信息系统》的查询方法和分析模型,进行“时间序列分析”和“同质同类比较分析”,可以挖掘出更多有用的监管信息;通过Excel中强大的函数库,可以获得更多的统计分析结果;通过《马克威分析系统》等专业分析软件,可以从海量信息和数据中寻找规律和知识,建立起概念模型,为决策者提供科学的决策依据。
分析实例六:2009年全国贷款总额预测。根据2002年至2008年一季度贷款余额和全年贷款总量,以及2009年一季度的贷款余额,可以用回归分析预测出2009年贷款总量。如下表所示:
|
金融机构人民币信贷收支表(单位:亿元)
|
||||
|
年份
|
一季度贷款各项余额
|
全年各项贷款余额
|
一季度同比增加
|
全年同比增加
|
|
2002
|
116255.00
|
131293.93
|
|
|
|
2003
|
139436.56
|
158996.23
|
23181.56
|
27702.30
|
|
2004
|
167442.53
|
177363.49
|
28005.97
|
18367.26
|
|
2005
|
185461.32
|
194690.39
|
18018.79
|
17326.90
|
|
2006
|
206394.59
|
225285.28
|
20933.27
|
30594.89
|
|
2007
|
239585.58
|
261690.88
|
33190.99
|
36405.60
|
|
2008
|
275000.21
|
303394.64
|
35414.63
|
41703.76
|
|
2009
|
349554.82
|
382661.64
|
74554.61
|
79267.00
|
表中用回归分析预测函数FORECAST预测了2009年的全年贷款总量,FORECAST(x,known_y's,known_x's)中的x是2009年一季度贷款余额;known_y's是2003至2008年的贷款总量,是因变量;known_x's是2003至2008年一季度贷款余额,是对应的自变量。
在表中,如果计算同比增加量,2009年全年同比增加贷款8万亿元左右。
如果以时间作为自变量,全年各项贷款余额作为因变量,画出全年贷款余额折线图和三阶趋势线,我们发现,决定系统R2=0.9984,接近于1,表示线性拟合程度较高。
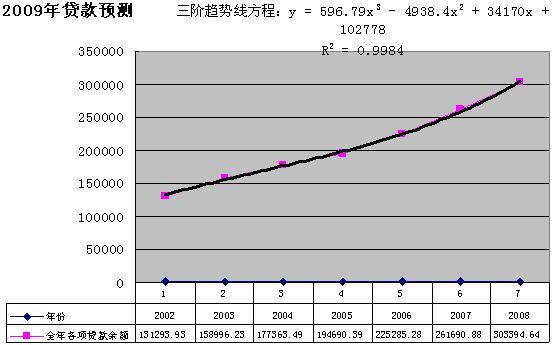
单考虑时间因素,设x=8,则y=365636.88(亿元)。表明:2009年贷款余额将超过36万亿元。同比年增加6万亿元。考虑到出口减少,外汇储备下降,货币生成机制发生变化,企业更加依赖银行贷款等因素,贷款余额将远不止36万亿元。